판다스 사용시 모듈 불러오기
import pandas as 약칭(보통 pd)
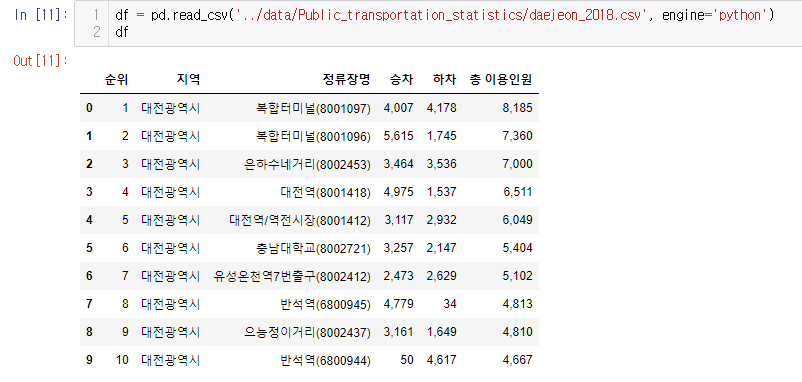
▶데이터프레임 불러오기
데이터프레임명 = pd.read_csv('경로.csv')
한글정보는 인코딩 오류가 난다. 옵션으로 engine='python' 붙여주는걸로 해결되었다. 이걸로 해결 안되는 경우도 있음.
상위 디렉토리로 가야하는 경우 ../ 을 이용한다.
파일 경로의 폴더 및 파일명은 가급적 영어로 맞춰두자.
▶데이터프레임 생성하기
방법1. 딕셔너리 리스트 사용
딕셔너리리스트명 = [
{'항목1' : 값1, '항목2 ': 값2 ... , '항목n' : 값n},
{'항목1' : 값1, '항목2 ': 값2 ... , '항목n' : 값n},
... ,
{'항목1' : 값1, '항목2 ': 값2 ... , '항목n' : 값n}
]
데이터프레임명 = pd.DataFrame(딕셔너리리스트명)
*헤더 순서 설정 시
데이터프레임명 = 데이터프레임명[['헤더1', '헤더2', ..., '헤더n']]
을 덧붙여준다.
예)
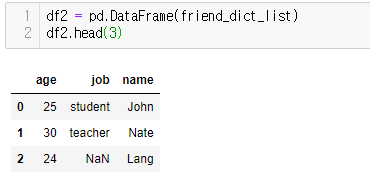
friend_dict_list = [
{'name': 'John', 'age' : 25, 'job': 'student'},
{'name': 'Nate', 'age' : 30, 'job': 'teacher'},
{'name': 'Lang', 'age' : 24},
{'name': 'Dan', 'age' : 26, 'job': 'worker'}
]
df = pd.DataFrame(friend_dict_list)
df = df[['name', 'age', 'job']]
방법2. Ordered dictionary 사용
from collections import OrderedDict
정렬딕셔너리명 = OrderedDict(
[
('항목1', [값1, 값2, ... , 값n]),
('항목1', [값1, 값2, ... , 값n]),
...,
('항목1', [값1, 값2, ... , 값n])
]
)
데이터프레임명 = pd.DataFrame.from_dict(정렬딕셔너리명)
예)
from collections import OrderedDict
freind_ordered_dict = OrderedDict(
[
('name', ['John', 'Nate', 'Lang', 'Dan']),
('age', [25, 30, 24, 26]),
('job', ['student', 'teacher', '', 'worker'])
]
)
df = pd.DataFrame.from_dict(freind_ordered_dict)
방법3. 리스트 사용
리스트명 = [
['값1', '값2', .... '값n'],
['값1', '값2', .... '값n'],
...,
['값1', '값2', .... '값n']
]
칼럼리스트명 = ['헤더1', '헤더2', ..., '헤더n']
데이터프레임명 = pd.DataFrame.from_records(리스트명, 칼럼리스트명)
예)
friend_list = [
['John', 25, 'student'],
['Nate', 30, 'teacher'],
['Lang', 24, ''],
['Dan', 26, 'worker']
]
column_name = ['name', 'age', 'job']
df = pd.DataFrame.from_records(friend_list, columns = column_name)
▶데이터프레임 보기
기본적으로는 데이터프레임 이름만을 입력하면 된다.
상위 5개 보기
데이터프레임명.head()
괄호에 숫자를 넣으면 그 수만큼 출력된다.
하위 5개 보기
데이터프레임명.tail()
괄호에 숫자를 넣으면 그 수만큼 출력된다.
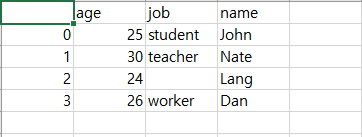
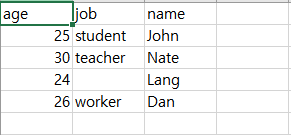
▶데이터프레임을 파일로 내보내어 저장하기
데이터프레임이름.to_csv('파일명.csv')
부가옵션
index=True/False - 인덱스 번호 표기. 기본 True
header=True/False - 데이터의 헤더 표기. 기본 True
na_rep = '-' -값이 없는 null 표기방법. 기본 공백.
예) df.to_csv('filename.csv', index=False, na_rep='none')
'데이터' 카테고리의 다른 글
| 판다스(pandas) - 데이터프레임 행, 열 선택/필터/삭제하기 (0) | 2020.03.09 |
|---|